请注意,本文编写于 316 天前,最后修改于 316 天前,其中某些信息可能已经过时。
目录
代替 ElasticSearch ~
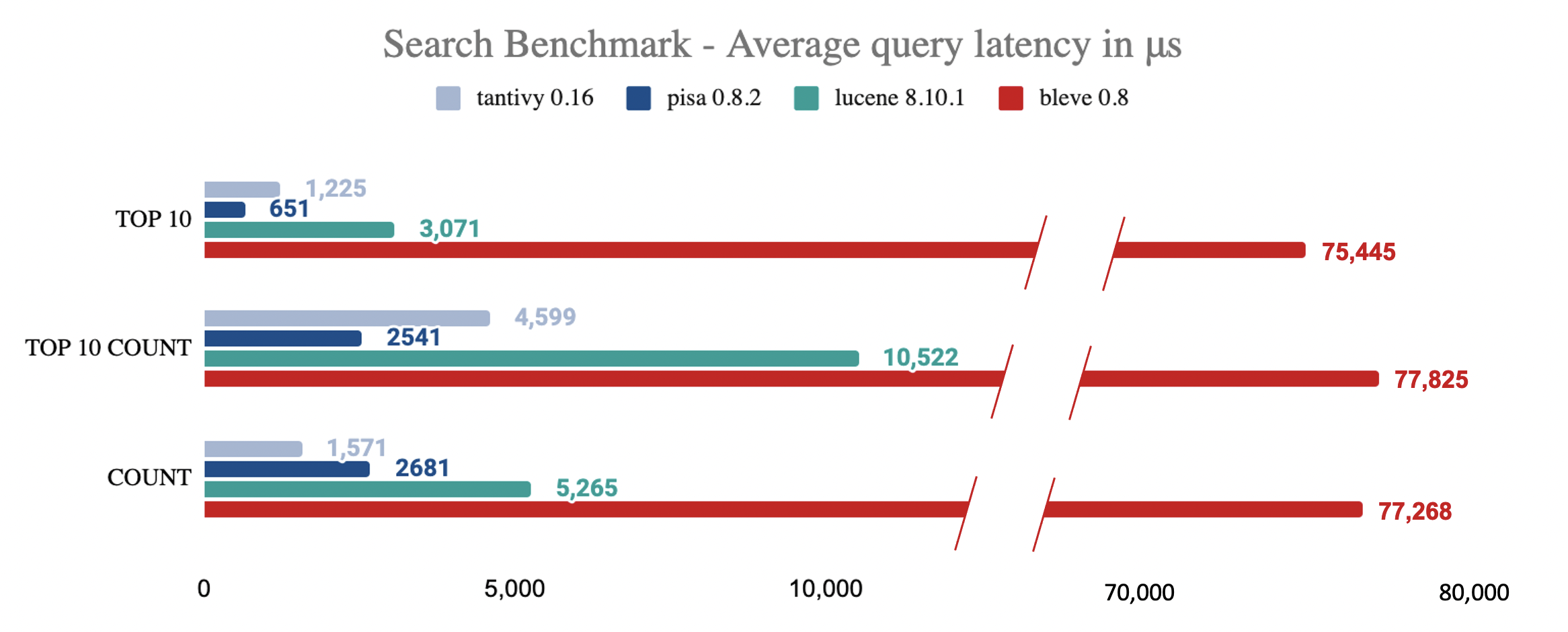
引入
tomltantivy = "0.22"
jieba-rs = "0.6"
分词器
一、三种模式对比总览
| 模式 | 名称 | 特点 | 适用场景 | 示例 |
|---|---|---|---|---|
| cut() | 精确模式 | 最细粒度切分,尽量不重复、不冗余 | 正常文本处理、文档索引 | "我爱北京天安门" → ["我", "爱", "北京", "天安门"] |
| cut_all() | 全模式 | 尽可能多地切出所有可能的词 | 快速召回、粗筛 | "我爱北京天安门" → ["我", "爱", "北京", "天安门", "京天", "安门"] |
| cut_for_search() | 搜索引擎模式 | 在精确基础上,进一步拆分长词,提升召回 | Tantivy 搜索索引推荐使用 | "我爱北京天安门" → ["我", "爱", "北京", "天安", "安门", "天安门"] |
-
cut() —— 精确模式(默认) 目标:最符合语言学规律的切分,避免歧义和冗余。 策略:基于 HMM(隐马尔可夫模型)+ 词典匹配,优先选择概率最高的切分方式。 适合:语义理解、摘要生成、正式文档处理。
-
cut_all() —— 全模式 目标:把所有可能的词都切出来,不管是否合理。 策略:暴力穷举所有出现在词典中的子串。 适合:快速检索、关键词提取、非精准场景。
-
cut_for_search() —— 搜索引擎模式 ✅ 推荐用于 Tantivy! 目标:在精确模式基础上,对长词进行二次拆分,提高搜索召回率。 策略: 保留完整词(如“天安门”) 同时拆出其前缀/后缀组合(如“天安”、“安门”) 避免无意义组合(如“京天”不会出现)
| 阶段 | 使用模式 | 说明 |
|---|---|---|
| 索引构建 | cut_all() | 把每个词及其子串都存入索引,最大化召回 |
| 查询解析 | cut_for_search() | 提高搜索召回率 |
| 展示结果 | cut() | 显示原始句子或精炼摘要时用精确模式 |
rust//! 中文分词器模块 - 提供高性能的中英文混合分词功能
use std::sync::Arc;
use jieba_rs::Jieba;
use lazy_static::lazy_static;
use tantivy::tokenizer::{Token, TokenStream, Tokenizer};
// 使用全局静态 Jieba 实例,避免重复初始化
lazy_static! {
static ref JIEBA: Arc<Jieba> = {
let jieba = Jieba::new();
// 可以在这里加载自定义词典
// 注意:jieba-rs 的 load_dict 需要可变引用和 BufRead
// 如果需要加载自定义词典,应该在初始化时处理
Arc::new(jieba)
};
}
/// 分词模式
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
pub enum SegmentationMode {
/// 精确模式:适合文本分析
// Precise,
/// 搜索模式:适合搜索引擎(召回率高但较慢)
Search,
/// 快速模式:速度优先(推荐用于大量文本)
// Fast,
/// 全模式:速度较慢,但能识别更多的词汇
All,
}
impl Default for SegmentationMode {
fn default() -> Self {
SegmentationMode::Search
}
}
/// 快速中文分词器 - 针对性能优化
#[derive(Clone)]
pub struct FastChineseTokenizer {
mode: SegmentationMode,
}
impl FastChineseTokenizer {
/// 创建新的分词器
pub fn new(mode: SegmentationMode) -> Self {
FastChineseTokenizer { mode }
}
/// 创建精确模式分词器
// pub fn precise() -> Self {
// Self::new(SegmentationMode::Precise)
// }
// /// 创建搜索模式分词器
// pub fn search() -> Self {
// Self::new(SegmentationMode::Search)
// }
/// 创建快速模式分词器
// pub fn fast() -> Self {
// Self::new(SegmentationMode::Fast)
// }
/// 创建全模式分词器
pub fn all() -> Self {
Self::new(SegmentationMode::All)
}
/// 执行分词
pub fn segment(&self, text: &str) -> Vec<String> {
match self.mode {
SegmentationMode::Search => {
// 搜索模式:使用 cut_for_search,召回率高
JIEBA.cut_for_search(text, false).into_iter().map(|s| s.to_string()).collect()
}
// SegmentationMode::Precise => {
// // 精确模式:使用标准 cut
// JIEBA.cut(text, false).into_iter().map(|s| s.to_string()).collect()
// }
// SegmentationMode::Fast => {
// // 快速模式:使用 cut 并过滤短词
// JIEBA
// .cut(text, false)
// .into_iter()
// .filter(|s| {
// // 保留长度大于1的词,或者非ASCII字符(中文单字)
// s.len() > 1 || !s.chars().all(|c| c.is_ascii())
// })
// .map(|s| s.to_string())
// .collect()
// }
SegmentationMode::All => JIEBA.cut_all(text).into_iter().map(|s| s.to_string()).collect(),
}
}
}
impl Tokenizer for FastChineseTokenizer {
type TokenStream<'a> = ChineseTokenStream<'a>;
fn token_stream<'a>(&'a mut self, text: &'a str) -> Self::TokenStream<'a> {
let tokens = self.segment(text);
ChineseTokenStream::new(tokens)
}
}
/// 中英文混合分词器
// #[derive(Clone)]
// pub struct ChineseEnglishTokenizer {
// mode: SegmentationMode,
// }
// impl ChineseEnglishTokenizer {
// /// 创建新的分词器
// pub fn new() -> Self {
// ChineseEnglishTokenizer { mode: SegmentationMode::default() }
// }
// /// 使用指定模式创建分词器
// pub fn with_mode(mode: SegmentationMode) -> Self {
// ChineseEnglishTokenizer { mode }
// }
// /// 执行分词
// fn segment(&self, text: &str) -> Vec<String> {
// match self.mode {
// SegmentationMode::Search => JIEBA.cut_for_search(text, false).into_iter().map(|s| s.to_string()).collect(),
// SegmentationMode::All => JIEBA.cut_all(text).into_iter().map(|s| s.to_string()).collect(),
// // SegmentationMode::Precise => JIEBA.cut(text, false).into_iter().map(|s| s.to_string()).collect(),
// // SegmentationMode::Fast => {
// // // 快速模式下,对中英文进行特殊处理
// // let mut tokens = Vec::new();
// // let mut current_word = String::new();
// // let mut is_english = false;
// // for ch in text.chars() {
// // if ch.is_ascii_alphanumeric() {
// // if !is_english && !current_word.is_empty() {
// // // 从中文切换到英文,先处理中文部分
// // let chinese_tokens = JIEBA.cut(¤t_word, false).into_iter().map(|s| s.to_string());
// // tokens.extend(chinese_tokens);
// // current_word.clear();
// // }
// // is_english = true;
// // current_word.push(ch);
// // } else if ch.is_whitespace() {
// // if !current_word.is_empty() {
// // tokens.push(current_word.clone());
// // current_word.clear();
// // }
// // is_english = false;
// // } else {
// // if is_english && !current_word.is_empty() {
// // // 从英文切换到中文,先保存英文部分
// // tokens.push(current_word.clone());
// // current_word.clear();
// // }
// // is_english = false;
// // current_word.push(ch);
// // }
// // }
// // // 处理最后的部分
// // if !current_word.is_empty() {
// // if is_english {
// // tokens.push(current_word);
// // } else {
// // let chinese_tokens = JIEBA.cut(¤t_word, false).into_iter().map(|s| s.to_string());
// // tokens.extend(chinese_tokens);
// // }
// // }
// // tokens
// // }
// }
// }
// }
// impl Default for ChineseEnglishTokenizer {
// fn default() -> Self {
// Self::new()
// }
// }
// impl Tokenizer for ChineseEnglishTokenizer {
// type TokenStream<'a> = ChineseTokenStream<'a>;
// fn token_stream<'a>(&'a mut self, text: &'a str) -> Self::TokenStream<'a> {
// let tokens = self.segment(text);
// ChineseTokenStream::new(tokens)
// }
// }
/// Token stream for Chinese text
pub struct ChineseTokenStream<'a> {
tokens: Vec<String>,
current_index: usize,
current_offset: usize,
token: Token,
_phantom: std::marker::PhantomData<&'a ()>,
}
impl<'a> ChineseTokenStream<'a> {
fn new(tokens: Vec<String>) -> Self {
ChineseTokenStream {
tokens,
current_index: 0,
current_offset: 0,
token: Token::default(),
_phantom: std::marker::PhantomData,
}
}
}
impl<'a> TokenStream for ChineseTokenStream<'a> {
fn advance(&mut self) -> bool {
while self.current_index < self.tokens.len() {
let token_text = &self.tokens[self.current_index];
self.current_index += 1;
// 跳过空的token
if token_text.trim().is_empty() {
self.current_offset += token_text.len();
continue;
}
let start = self.current_offset;
let end = start + token_text.len();
self.token.text.clear();
self.token.text.push_str(token_text);
self.token.offset_from = start;
self.token.offset_to = end;
self.token.position = self.token.position.wrapping_add(1);
self.current_offset = end;
return true;
}
false
}
fn token(&self) -> &Token {
&self.token
}
fn token_mut(&mut self) -> &mut Token {
&mut self.token
}
}
// #[cfg(test)]
// mod tests {
// use std::time::Instant;
// use super::*;
// #[test]
// fn test_fast_tokenizer() {
// let mut tokenizer = FastChineseTokenizer::fast();
// let text = "我爱北京天安门";
// let mut stream = tokenizer.token_stream(text);
// let mut tokens = Vec::new();
// while stream.advance() {
// tokens.push(stream.token().text.clone());
// }
// assert!(!tokens.is_empty());
// println!("Fast mode tokens: {:?}", tokens);
// }
// #[test]
// fn test_chinese_english_tokenizer() {
// let mut tokenizer = ChineseEnglishTokenizer::new();
// let text = "Hello世界,这是一个test测试";
// let mut stream = tokenizer.token_stream(text);
// let mut tokens = Vec::new();
// while stream.advance() {
// tokens.push(stream.token().text.clone());
// }
// assert!(!tokens.is_empty());
// println!("Mixed text tokens: {:?}", tokens);
// // 应该包含英文和中文的分词结果
// assert!(tokens.iter().any(|t| t == "Hello"));
// assert!(tokens.iter().any(|t| t.contains("世界") || t == "世界"));
// }
// #[test]
// fn test_segmentation_modes() {
// let text = "中华人民共和国国家标准";
// // 测试不同模式
// let modes = vec![
// (SegmentationMode::Fast, "Fast"),
// (SegmentationMode::Precise, "Precise"),
// (SegmentationMode::Search, "Search"),
// ];
// for (mode, name) in modes {
// let mut tokenizer = FastChineseTokenizer::new(mode);
// let mut stream = tokenizer.token_stream(text);
// let mut tokens = Vec::new();
// while stream.advance() {
// tokens.push(stream.token().text.clone());
// }
// println!("{} mode tokens: {:?}", name, tokens);
// assert!(!tokens.is_empty());
// }
// }
// #[test]
// fn test_performance_comparison() {
// let text = "我爱北京天安门,天安门上太阳升。伟大领袖毛主席,指引我们向前进。";
// let iterations = 1000;
// // 测试快速模式
// let mut fast_tokenizer = FastChineseTokenizer::all();
// let start = Instant::now();
// for _ in 0..iterations {
// let mut stream = fast_tokenizer.token_stream(text);
// while stream.advance() {}
// }
// let fast_duration = start.elapsed();
// // 测试搜索模式
// let mut search_tokenizer = FastChineseTokenizer::search();
// let start = Instant::now();
// for _ in 0..iterations {
// let mut stream = search_tokenizer.token_stream(text);
// while stream.advance() {}
// }
// let search_duration = start.elapsed();
// println!(
// "All mode: {:?} for {} iterations",
// fast_duration, iterations
// );
// println!(
// "Search mode: {:?} for {} iterations",
// search_duration, iterations
// );
// // 注意:实际性能可能因环境和数据而异
// // 这里只验证两种模式都能正常工作
// assert!(fast_duration.as_millis() > 0);
// assert!(search_duration.as_millis() > 0);
// }
// #[test]
// fn test_english_only() {
// let mut tokenizer = ChineseEnglishTokenizer::new();
// let text = "Hello World This Is A Test";
// let mut stream = tokenizer.token_stream(text);
// let mut tokens = Vec::new();
// while stream.advance() {
// tokens.push(stream.token().text.clone());
// }
// assert!(!tokens.is_empty());
// println!("English only tokens: {:?}", tokens);
// }
// #[test]
// fn test_chinese_only() {
// let mut tokenizer = ChineseEnglishTokenizer::new();
// let text = "这是一个纯中文的测试文本";
// let mut stream = tokenizer.token_stream(text);
// let mut tokens = Vec::new();
// while stream.advance() {
// tokens.push(stream.token().text.clone());
// }
// assert!(!tokens.is_empty());
// println!("Chinese only tokens: {:?}", tokens);
// }
// }
搜索引擎
rustuse std::{
collections::HashMap, path::Path, sync::{Arc, RwLock}
};
use lazy_static::lazy_static;
use tantivy::{
collector::TopDocs, doc, query::{BooleanQuery, Occur, Query, TermQuery}, schema::{Field, IndexRecordOption, Schema, TextFieldIndexing, TextOptions, Value as _}, Index, Result, TantivyDocument, Term
};
use super::chinese_tokenizer;
const INDEX_PATH: &str = "data/tantivy_index";
const ALL_TOKENIZER: &str = "all";
const FIELD_NAME: &str = "content";
const INDEX_WRITER_MEMORY: usize = 50_000_000;
const DOCUMENT_BATCH_SIZE: usize = 100;
const MAX_SEGMENT_CACHE_SIZE: usize = 10000;
const SEARCH_LIMIT: usize = 10;
lazy_static! {
/// 全局分词缓存
static ref SEGMENT_CACHE: Arc<RwLock<SegmentCache>> =
Arc::new(RwLock::new(SegmentCache::new()));
}
pub struct SegmentCache {
cache: HashMap<String, Vec<String>>,
max_size: usize,
hits: usize,
misses: usize,
}
impl SegmentCache {
/// 创建新的缓存实例
pub fn new() -> Self {
Self::with_capacity(MAX_SEGMENT_CACHE_SIZE)
}
/// 创建指定容量的缓存实例
pub fn with_capacity(max_size: usize) -> Self {
SegmentCache { cache: HashMap::new(), max_size, hits: 0, misses: 0 }
}
/// 获取缓存项
fn get(&mut self, key: &str) -> Option<Vec<String>> {
if let Some(value) = self.cache.get(key) {
self.hits += 1;
Some(value.clone())
} else {
self.misses += 1;
None
}
}
/// 插入缓存项
fn insert(&mut self, key: String, value: Vec<String>) {
// 如果缓存已满,清空缓存
if self.cache.len() >= self.max_size {
self.cache.clear();
}
self.cache.insert(key, value);
}
}
/// create new index
///
/// delete if it exists
pub fn create_index() -> Result<(Schema, Index)> {
let schema = build_schema();
let path = Path::new(INDEX_PATH);
if path.exists() {
std::fs::remove_dir_all(path)?;
}
if !path.exists() {
std::fs::create_dir_all(path)?;
}
let index = Index::create_in_dir(path, schema.clone())?;
register_tokenizers(&index);
Ok((schema, index))
}
pub async fn write_documents(index: &Index, schema: &Schema, contents: &[String]) -> tantivy::Result<()> {
let mut index_writer = index.writer(INDEX_WRITER_MEMORY)?;
let mut docs_batch = Vec::with_capacity(DOCUMENT_BATCH_SIZE);
for content in contents {
let doc = create_document(content, schema);
docs_batch.push(doc);
if docs_batch.len() >= DOCUMENT_BATCH_SIZE {
for doc in docs_batch.drain(..) {
index_writer.add_document(doc)?;
}
}
}
for doc in docs_batch {
index_writer.add_document(doc)?;
}
index_writer.commit()?;
Ok(())
}
pub async fn search(index: &Index, schema: &Schema, query: &str) -> anyhow::Result<Vec<String>> {
let searcher = index.reader()?.searcher();
let tantivy_query = build_query(query, schema)?;
let top_docs = searcher.search(&tantivy_query, &TopDocs::with_limit(SEARCH_LIMIT))?;
let mut results = vec![];
for (_score, doc_address) in top_docs {
let retrieved_doc: TantivyDocument = searcher.doc(doc_address)?;
if let Some(content) = retrieved_doc
.get_first(get_field(schema))
.and_then(|field_value| field_value.as_str())
.map(|s| s.to_string())
{
results.push(content);
}
}
Ok(results)
}
fn build_query(input: &str, schema: &Schema) -> tantivy::Result<Box<dyn Query>> {
let mut subqueries: Vec<(Occur, Box<dyn Query>)> = Vec::new();
let segmented_words = segment_with_cache(input, chinese_tokenizer::SegmentationMode::Search);
for word in segmented_words {
let term_query = TermQuery::new(
Term::from_field_text(get_field(schema), &word),
IndexRecordOption::Basic,
);
subqueries.push((Occur::Should, Box::new(term_query)));
}
Ok(Box::new(BooleanQuery::new(subqueries)))
}
fn create_document(content: &str, schema: &Schema) -> TantivyDocument {
doc! {
get_field(schema) => content,
}
}
fn get_field(schema: &Schema) -> Field {
schema.get_field(FIELD_NAME).unwrap_or_else(|_| panic!("Field '{}' not found in schema", FIELD_NAME))
}
pub fn segment_with_cache(text: &str, mode: chinese_tokenizer::SegmentationMode) -> Vec<String> {
let cache_key = format!("{}:{:?}", text, mode);
// 尝试从缓存读取
{
let mut cache = SEGMENT_CACHE.write().unwrap();
if let Some(cached) = cache.get(&cache_key) {
return cached;
}
}
// 如果缓存未命中,进行分词
let segments = perform_segmentation(text, mode);
// 存入缓存
{
let mut cache = SEGMENT_CACHE.write().unwrap();
cache.insert(cache_key, segments.clone());
}
segments
}
fn perform_segmentation(text: &str, mode: chinese_tokenizer::SegmentationMode) -> Vec<String> {
chinese_tokenizer::FastChineseTokenizer::new(mode).segment(text)
}
fn register_tokenizers(index: &Index) {
let all_tokenizer = chinese_tokenizer::FastChineseTokenizer::all();
index.tokenizers().register(ALL_TOKENIZER, all_tokenizer);
}
fn build_schema() -> Schema {
let mut schema_builder = Schema::builder();
let text_options = TextOptions::default()
.set_indexing_options(
TextFieldIndexing::default()
.set_tokenizer(ALL_TOKENIZER)
.set_index_option(IndexRecordOption::WithFreqsAndPositions),
)
.set_stored();
schema_builder.add_text_field(FIELD_NAME, text_options);
schema_builder.build()
}
封装
rustuse std::{
fs::{File, OpenOptions}, io::Write, path::Path, sync::Arc
};
use anyhow::Ok;
use memmap2::MmapOptions;
use tantivy::{schema::Schema, Index};
mod chinese_tokenizer;
mod tantivy_engine;
use lazy_static::lazy_static;
use memchr::memmem;
lazy_static! {
pub static ref SEARCH_ENGINE: Arc<SearchEngine> = Arc::new(SearchEngine::new());
}
const DEFAULT_KNOWLEDGE_FILE: &str = "data/knowledge.txt";
#[derive(Debug, Clone)]
pub struct SearchEngine {
index: Index,
schema: Schema,
}
impl SearchEngine {
fn new() -> Self {
let (schema, index) = tantivy_engine::create_index().unwrap();
Self { index, schema }
}
pub async fn init(&self) -> anyhow::Result<()> {
if Path::new(DEFAULT_KNOWLEDGE_FILE).exists() {
let content_str = std::fs::read_to_string(DEFAULT_KNOWLEDGE_FILE)?;
let contents = content_str.split("\n").map(|s| s.trim().to_string()).collect::<Vec<String>>();
tantivy_engine::write_documents(&self.index, &self.schema, &contents).await?;
}
Ok(())
}
pub async fn write(&self, content: &str) -> anyhow::Result<()> {
if !Path::new(DEFAULT_KNOWLEDGE_FILE).exists() {
std::fs::write(DEFAULT_KNOWLEDGE_FILE, content)?;
} else {
let needle = content.as_bytes();
let file = File::open(DEFAULT_KNOWLEDGE_FILE)?;
let mmap = unsafe { MmapOptions::new().map(&file)? };
if memmem::find(&mmap, needle).is_some() {
return Ok(());
}
let mut file = OpenOptions::new().create(true).append(true).open(DEFAULT_KNOWLEDGE_FILE)?;
writeln!(file, "{}", content)?;
}
tantivy_engine::write_documents(&self.index, &self.schema, &vec![content.to_string()]).await?;
Ok(())
}
pub async fn search(&self, query: &str) -> anyhow::Result<Vec<String>> {
let results = tantivy_engine::search(&self.index, &self.schema, query).await?;
Ok(results)
}
}
使用
封装一个 mcp server tool 吧~
读、写笔记
rust#[tool(
description = "Searches the user’s personal notes for content matching a natural language query. Call this tool when the user asks to find, look up, recall, or review anything they’ve written before — for example: “Where did I write about the trip to Japan?”, “Show me my todos from Monday”, “Find notes with the tag #design”, or “What did I say about the new API?” Do NOT call this tool for factual questions that aren’t about the user’s own notes (e.g., “Who invented the light bulb?”). This tool only accesses the user’s private note collection."
)]
async fn search_info(&self, Parameters(req): Parameters<QueryRequest>) -> Result<CallToolResult, McpError> {
let results = SEARCH_ENGINE.search(&req.query).await.unwrap_or(vec!["未搜索到内容".to_string()]);
Ok(CallToolResult::success(vec![Content::text(
results.join("\n"),
)]))
}
#[tool(
description = "Creates a new personal note from user-provided content. Call this tool when the user says they want to save, record, log, or write down anything for future reference — e.g., “Save this idea: build a morning routine app”, “Note that my cat hates thunder”, or “Add to my todo list: call dentist”. Do not use for generating content, replying to questions, or casual chatting. Only invoke when the intent is to preserve information long-term."
)]
async fn record_info(&self, Parameters(req): Parameters<RecordRequest>) -> Result<CallToolResult, McpError> {
let result = match SEARCH_ENGINE.write(&req.content).await {
Ok(_) => "写入成功".to_string(),
Err(err) => format!("写入失败: {}", err),
};
Ok(CallToolResult::success(vec![Content::text(result)]))
}
如果对你有用的话,可以打赏哦
打赏


本文作者:42tr
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录