目录
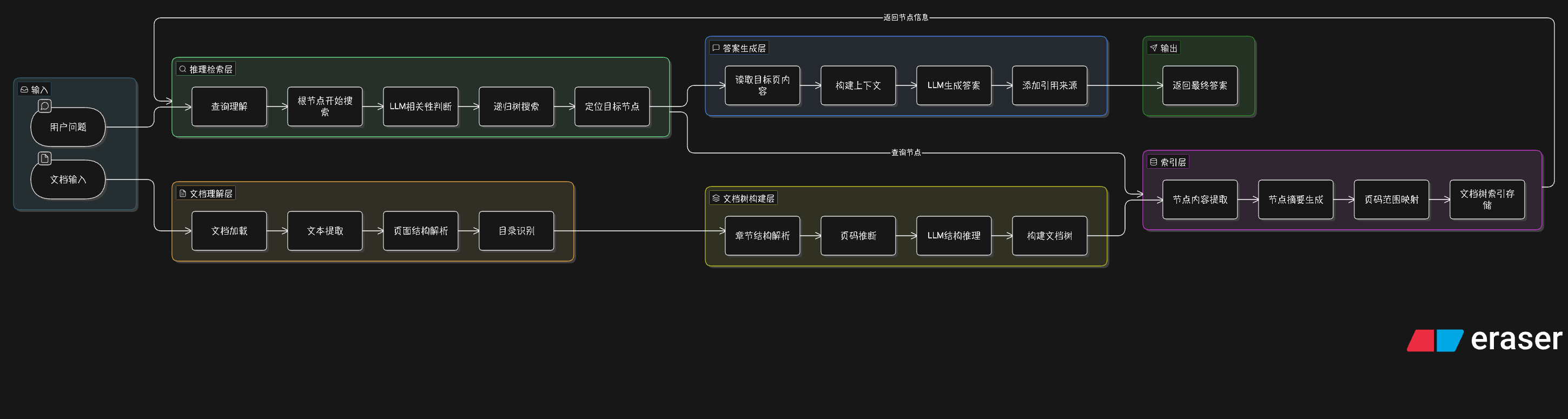
PageIndex 的核心目标是解决一个问题:
如何让 LLM 高质量理解长文档,并实现精准搜索。
传统 RAG 的问题:
- 文档 chunk 切得很碎
- 结构信息丢失
- 搜索结果上下文不完整
- LLM 容易产生幻觉
PageIndex 的思路是:
先理解文档结构 → 再建立树状索引 → 再做向量搜索
而不是直接 chunk。
整个系统可以拆成两个阶段:
离线阶段(Indexing)
文档解析 → 结构提取 → 索引构建 → 向量存储
在线阶段(Query)
用户问题 → 向量搜索 → 结构补全 → LLM回答
一、文档解析流程(Document Parsing)
文档解析的目标是:
把 PDF / Word / Markdown 转换成可理解的结构化数据
典型输入:
- Word
- Markdown
- HTML
解析流程如下。
1 文档加载
首先系统加载原始文档。
核心任务:
- 读取文档
- 转换为文本
- 保留基础结构
可能用到的工具:
- pdf parser
- docx parser
- html parser
输出类似:
json{
"pages": [
{
"text": "...",
"layout": "..."
}
]
}
此时仍然是原始文本。
2 文档结构解析
接下来需要识别文档结构。
系统会识别:
- 标题(H1 / H2 / H3)
- 段落
- 列表
- 表格
- 代码块
例如:
原文:
markdown1. Introduction
This paper introduces...
2. Method
会被解析成:
json[
{ "type": "heading", "level": 1, "text": "Introduction" },
{ "type": "paragraph", "text": "This paper introduces..." },
{ "type": "heading", "level": 1, "text": "Method" }
]
这一步的意义是:
恢复文档逻辑结构。
3 LLM 推理生成初始目录
如果文档结构不明显(很多 PDF 都这样),系统会调用 LLM。
让 LLM:
根据文本推断文档目录结构
例如:
输入:
txt大量文本
输出:
txt1 Introduction 2 Background 3 Method 4 Experiment
这一步得到:
Document Outline
也就是 初始目录线索。
4 构建文档树(Document Tree)
有了标题信息之后,就可以生成 文档树结构。
例如:
txtDocument ├── Introduction │ ├── paragraph │ └── paragraph │ ├── Method │ ├── subsection │ └── subsection │ └── Experiment
内部结构通常是:
Node { title level content children }
这样每一段文本都有:
- 父节点
- 子节点
- 层级关系
这就是 PageIndex 的核心结构。
5 文档 Chunk 切分
接下来系统会生成检索单元。
但和传统 RAG 不同:
不是固定长度切分
而是:
按结构切分
例如:
Section Subsection Paragraph
形成 chunk:
chunk_1 = "Introduction section" chunk_2 = "Method subsection" chunk_3 = "Experiment subsection"
同时保留:
parent section path
例如:
path = Introduction > Background
这对于搜索非常重要。
6 Embedding 向量化
然后系统会对每个 chunk 生成向量存入向量库
7 构建索引
最终索引包含:
- text
- embedding
- tree path
- node id
- parent id
例如:
json{
"text": "...",
"vector": [...],
"path": "Method > Architecture",
"node_id": 123
}
到这里 离线阶段完成。
二、搜索流程(Query Pipeline)
当用户提问时,系统开始在线搜索流程。
1 Query 解析
用户输入:
How does the method work?
系统会:
- 清洗 query
- 生成 embedding
得到:
query vector
2 向量搜索
在向量数据库中查找 TopK 相似 chunk
返回:
Method section Architecture subsection Algorithm description
这是 第一层召回。
3 结构补全
如果只返回 chunk,LLM 很可能缺上下文。
所以 PageIndex 会:
- 补充父节点
- 补充兄弟节点
- 补充上下文
例如:
原始 chunk:
Algorithm Step 2
系统会扩展为:
Method └ Algorithm ├ Step1 ├ Step2 └ Step3
这样上下文完整。
4 上下文重排序
如果 chunk 很多,需要排序。
排序依据:
- embedding 相似度
- 文档结构距离
- LLM rerank
最终选择:Top N context
5 构造 LLM Prompt
系统构造 Prompt:
Context: [document chunks] Question: user query
例如:
Answer based on the following document.
6 LLM 生成答案
最后调用 LLM 输出:
final answer
同时可能附带:
- 引用来源
- section path
例如:
Source: Method > Architecture
三、核心算法
1. 文档树生成算法
核心思想:
把文档转换成类似 HTML DOM 的树结构
结构示意:
txtDocument ├── Section │ ├── Subsection │ │ ├── Paragraph │ │ └── Paragraph │ └── Subsection └── Section
每个节点都保存:
txtNode ├ id ├ title ├ content ├ level ├ parent └ children
构建流程通常是 三阶段。
1 结构元素检测
首先解析文本块类型:
- heading
- paragraph
- list
- table
- code
例如:
txt1 Introduction This paper proposes...
解析结果:
txtHeading(level=1) Paragraph
在 PDF 场景下,通常还会利用:
- 字体大小
- 字体粗细
- 行距
- 版面布局
来识别标题。
例如:
FontSize > 18 → H1 FontSize > 14 → H2
这样可以初步恢复文档结构。
2 层级推断
如果文档本身没有明确层级(很多 PDF 都是这样),就需要推断。
典型方法:
方法1:规则推断
例如:
txt1 1.1 1.1.1
直接转换成:
level1 level2 level3
方法2:LLM 推断
当结构不清晰时,让 LLM 推理:
输入:
大量文本片段
输出:
Possible outline: 1 Introduction 2 Background 3 Method
但注意:
不会把整个文档给 LLM。
而是:
抽样片段 + 标题候选
这样 token 很小。
3 树结构构建
当拿到标题层级之后,构建树结构。
伪代码:
stack = [] for element in elements: if element is heading: while stack.top.level >= element.level: stack.pop() stack.top.children.append(element) stack.push(element) else: stack.top.children.append(element)
最终得到:
Document Tree
优势:
- 结构清晰
- 支持父子检索
- 支持上下文扩展
搜索时的结构扩展策略
普通 RAG 的最大问题:
chunk 太碎
例如:
txtAlgorithm Step 2
LLM 根本不知道:
Step1 Step3
PageIndex 的解决办法是:
结构扩展(Structure Expansion)
流程如下。
1 初始向量召回
首先正常向量搜索:
query embedding ↓ vector search ↓ topK chunks
例如:
Chunk A Chunk B Chunk C
但这些 chunk 只是局部。
2 向上扩展(Parent Expansion)
系统会找:
父节点
例如:
原始结果:
Algorithm Step 2
扩展后:
Method └ Algorithm └ Step 2
这样 LLM 就知道:
这是 Method 章节里的算法
3 向下扩展(Child Expansion)
如果 chunk 是一个标题节点:
Algorithm
系统会补充:
Algorithm ├ Step1 ├ Step2 └ Step3
这样内容更完整。
4 兄弟节点扩展(Sibling Expansion)
有时需要增加相邻信息:
Step1 Step2 Step3
而不是只给:
Step2
这样能明显提高回答质量。
5 Token Budget 控制
扩展不是无限的。
系统会控制:
max_tokens
例如:
4000 tokens context
策略:
- 优先保留最相关 chunk
- 逐层扩展
- 直到 token 满
类似:
relevance-first expansion
LLM 生成目录为什么不会超上下文
很多人看到 PageIndex 的一个步骤:
LLM 推理生成文档目录
会有疑问:
文档几百页,LLM 怎么可能读完?
实际上它用了 分层策略。
1 文档分段
首先文档会被切成块:
chunk size ≈ 500 tokens
例如:
chunk1 chunk2 chunk3 ...
每个 chunk 单独分析。
2 局部目录生成
LLM 对每一小段生成:
local outline
例如:
chunk1 → Introduction chunk2 → Method chunk3 → Experiment
3 Outline 合并
系统再把这些 outline 合并:
merge outlines
类似:
map-reduce
过程:
local outline ↓ merge ↓ global outline
4 层级压缩
如果目录太长,还会压缩:
例如:
原始:
1 Introduction 1.1 Motivation 1.2 Background 2 Method 2.1 Architecture 2.2 Training
压缩为:
Introduction Method Experiment
这样 token 极小


本文作者:42tr
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!